Register reuse
In this version we are really starting to speed things up.
We will use a combination of ILP, SIMD, and loop unrolling to maximize CPU register usage in the hottest loop of the step_row function.
The Intel CPUs we are targeting have 16 AVX registers, each 256 bits wide, which match one-to-one with the f32x8 type we have been using.
We'll use the same approach as in the reference implementation, which is to load 6 f32x8 vectors from memory at each iteration and compute 9 results by combining all pairs.
Here is a visualization that shows the big picture of what is happening.
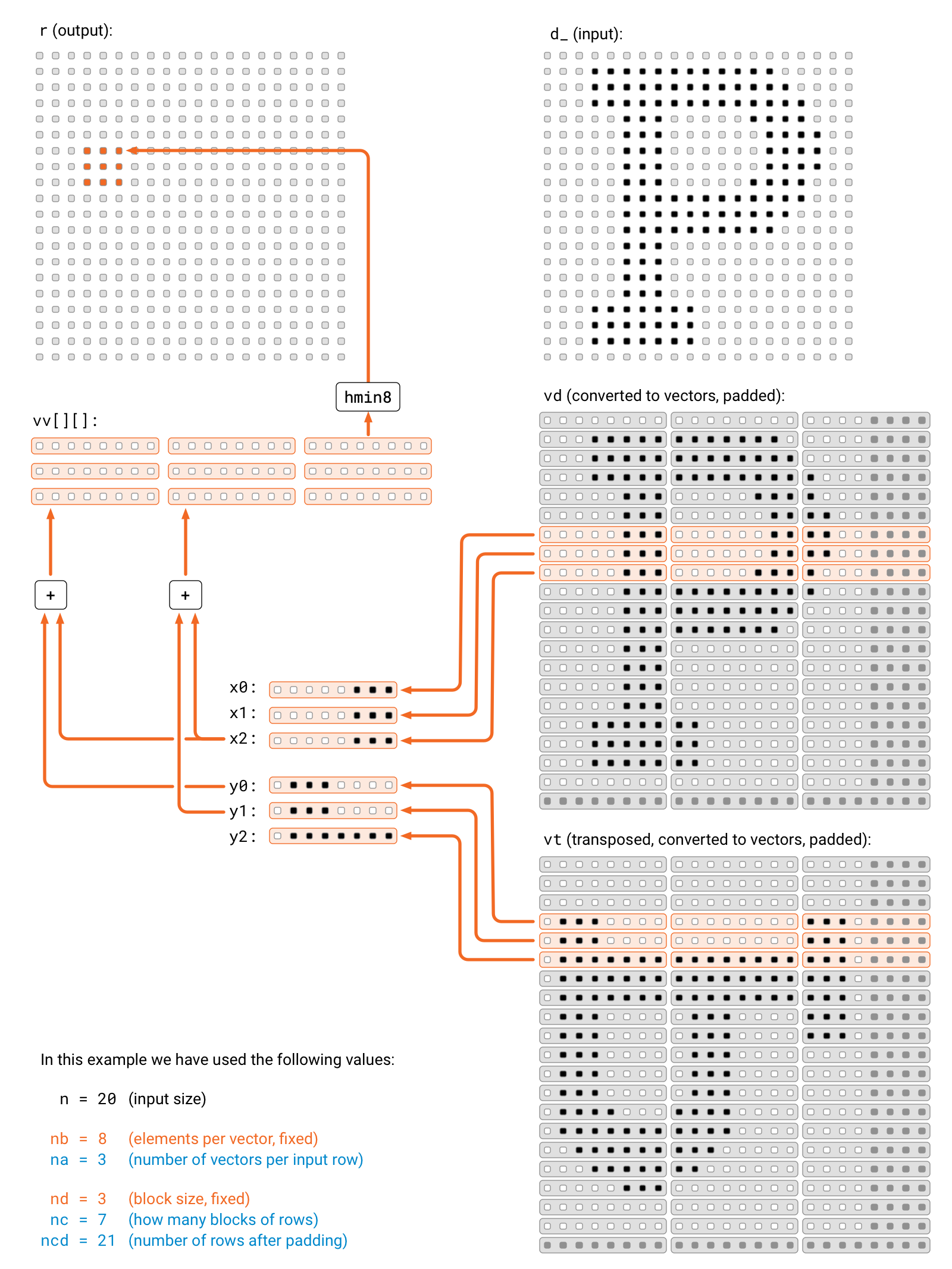{kind=link}
First, we will group all rows of vd and vt into blocks of 3 rows.
Then, for every pair of 3-row blocks, we read 3+3 f32x8s and accumulate 9 different, intermediate f32x8 results from the cartesian product of the vector pairs.
Finally, we extract values from the results accumulated in 9 f32x8s and write them to r in correct order.
The high-level idea is the same as in our other approaches: to do a bit of extra work outside the performance critical loop in order to do significantly less work inside the loop.
Implementing step_row_block
Like in v2, we need to add some padding to make the amount of rows divisible by 3.
This time, however, we add the padding at the bottom of vd and vt, since the blocks are grouped vertically, by row.
Preprocessing is almost exactly the same as in v3, we pack all elements of d as f32x8 vectors into vd and its transpose vt, except for the few extra rows at the bottom (unless the amount of rows is already divisible by 3):
const BLOCK_HEIGHT: usize = 3;
let blocks_per_col = (n + BLOCK_HEIGHT - 1) / BLOCK_HEIGHT;
let vecs_per_row = (n + simd::f32x8_LENGTH - 1) / simd::f32x8_LENGTH;
let padded_height = BLOCK_HEIGHT * blocks_per_col;
// Preprocess exactly as in v3_simd,
// but make sure the amount of rows is divisible by BLOCK_HEIGHT
let mut vd = std::vec![simd::f32x8_infty(); padded_height * vecs_per_row];
let mut vt = std::vec![simd::f32x8_infty(); padded_height * vecs_per_row];
Since we are processing rows in blocks of 3, it is probably easiest to also write results for 3 rows at a time.
Then we can chunk vd and r into 3-row blocks, zip them up, apply step_row_block in parallel such that each thread writes results for one block of 3 rows from vd into 3 rows of r.
Inside step_row_block, every thread will chunk vt into 3-row blocks, and computes results for every pair of vt row block j and vd row block i:
// Function: For a row block vd_row_block containing 3 rows of f32x8 vectors,
// compute results for all row combinations of vd_row_block and row blocks of vt
let step_row_block = |(i, (r_row_block, vd_row_block)): (usize, (&mut [f32], &[f32x8]))| {
// Chunk up vt into blocks exactly as vd
let vt_row_blocks = vt.chunks_exact(BLOCK_HEIGHT * vecs_per_row);
// Compute results for all combinations of row blocks from vd and vt
for (j, vt_row_block) in vt_row_blocks.enumerate() {
Then, for every pair of row blocks vd_row_block and vt_row_block, we iterate over their columns, computing all 9 combinations of 3 f32x8 vectors from vd_row_block and 3 f32x8 vectors from vt_row_block, and add the results to the 9 intermediate results.
Before we go into the most performance-critical loop, we initialize 9 intermediate results to f32x8 vectors (each containing 8 f32::INFINITYs), and extract all 6 rows from both row blocks:
// Partial results for 9 f32x8 row pairs
// All as separate variables to encourage the compiler
// to keep these values in 9 registers for the duration of the loop
let mut tmp0 = simd::f32x8_infty();
let mut tmp1 = simd::f32x8_infty();
let mut tmp2 = simd::f32x8_infty();
let mut tmp3 = simd::f32x8_infty();
let mut tmp4 = simd::f32x8_infty();
let mut tmp5 = simd::f32x8_infty();
let mut tmp6 = simd::f32x8_infty();
let mut tmp7 = simd::f32x8_infty();
let mut tmp8 = simd::f32x8_infty();
// Extract all rows from the row blocks
let mut vd_rows = vd_row_block.chunks_exact(vecs_per_row);
let mut vt_rows = vt_row_block.chunks_exact(vecs_per_row);
let (vd_row_0, vd_row_1, vd_row_2) = vd_rows.next_tuple().unwrap();
let (vt_row_0, vt_row_1, vt_row_2) = vt_rows.next_tuple().unwrap();
The reason we are not using a tmp array of 9 values is that the compiler was not keeping those 9 values in registers for the duration of the loop.
Now everything is set up for iterating column-wise, computing the usual "addition + minimum" between every element in vt and vd.
This time, we will load 6 f32x8 vectors at each iteration, and compute 9 results in total.
We'll use the izip-macro from the itertools crate to get a nice, flattened tuple of row elements at each iteration:
// Move horizontally, computing 3 x 3 results for each column
// At each iteration, load two 'vertical stripes' of 3 f32x8 vectors
let rows = izip!(vd_row_0, vd_row_1, vd_row_2, vt_row_0, vt_row_1, vt_row_2);
for (&d0, &d1, &d2, &t0, &t1, &t2) in rows {
// Combine all 9 pairs of f32x8 vectors from 6 rows at every column
tmp0 = simd::min(tmp0, simd::add(d0, t0));
tmp1 = simd::min(tmp1, simd::add(d0, t1));
tmp2 = simd::min(tmp2, simd::add(d0, t2));
tmp3 = simd::min(tmp3, simd::add(d1, t0));
tmp4 = simd::min(tmp4, simd::add(d1, t1));
tmp5 = simd::min(tmp5, simd::add(d1, t2));
tmp6 = simd::min(tmp6, simd::add(d2, t0));
tmp7 = simd::min(tmp7, simd::add(d2, t1));
tmp8 = simd::min(tmp8, simd::add(d2, t2));
}
After we have iterated over all columns, we offset the block row indexes i and j so that we get a proper index mapping to the indexes of r, extract final results from all 9 intermediate results, and finally write them to r:
let tmp = [tmp0, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7, tmp8];
// Set 9 final results for all combinations of 3 rows starting at i and 3 rows starting at j
for (block_i, (r_row, tmp_row)) in r_row_block.chunks_exact_mut(n).zip(tmp.chunks_exact(BLOCK_HEIGHT)).enumerate() {
for (block_j, &tmp_res) in tmp_row.iter().enumerate() {
let res_i = i * BLOCK_HEIGHT + block_i;
let res_j = j * BLOCK_HEIGHT + block_j;
if res_i < n && res_j < n {
// Reduce one f32x8 to the final result for one pair of rows
r_row[res_j] = simd::horizontal_min(tmp_res);
}
}
}
Full step_row_block implementation
// Function: For a row block vd_row_block containing 3 rows of f32x8 vectors,
// compute results for all row combinations of vd_row_block and row blocks of vt
let step_row_block = |(i, (r_row_block, vd_row_block)): (usize, (&mut [f32], &[f32x8]))| {
// Chunk up vt into blocks exactly as vd
let vt_row_blocks = vt.chunks_exact(BLOCK_HEIGHT * vecs_per_row);
// Compute results for all combinations of row blocks from vd and vt
for (j, vt_row_block) in vt_row_blocks.enumerate() {
// Partial results for 9 f32x8 row pairs
// All as separate variables to encourage the compiler
// to keep these values in 9 registers for the duration of the loop
let mut tmp0 = simd::f32x8_infty();
let mut tmp1 = simd::f32x8_infty();
let mut tmp2 = simd::f32x8_infty();
let mut tmp3 = simd::f32x8_infty();
let mut tmp4 = simd::f32x8_infty();
let mut tmp5 = simd::f32x8_infty();
let mut tmp6 = simd::f32x8_infty();
let mut tmp7 = simd::f32x8_infty();
let mut tmp8 = simd::f32x8_infty();
// Extract all rows from the row blocks
let mut vd_rows = vd_row_block.chunks_exact(vecs_per_row);
let mut vt_rows = vt_row_block.chunks_exact(vecs_per_row);
let (vd_row_0, vd_row_1, vd_row_2) = vd_rows.next_tuple().unwrap();
let (vt_row_0, vt_row_1, vt_row_2) = vt_rows.next_tuple().unwrap();
// Move horizontally, computing 3 x 3 results for each column
// At each iteration, load two 'vertical stripes' of 3 f32x8 vectors
let rows = izip!(vd_row_0, vd_row_1, vd_row_2, vt_row_0, vt_row_1, vt_row_2);
for (&d0, &d1, &d2, &t0, &t1, &t2) in rows {
// Combine all 9 pairs of f32x8 vectors from 6 rows at every column
tmp0 = simd::min(tmp0, simd::add(d0, t0));
tmp1 = simd::min(tmp1, simd::add(d0, t1));
tmp2 = simd::min(tmp2, simd::add(d0, t2));
tmp3 = simd::min(tmp3, simd::add(d1, t0));
tmp4 = simd::min(tmp4, simd::add(d1, t1));
tmp5 = simd::min(tmp5, simd::add(d1, t2));
tmp6 = simd::min(tmp6, simd::add(d2, t0));
tmp7 = simd::min(tmp7, simd::add(d2, t1));
tmp8 = simd::min(tmp8, simd::add(d2, t2));
}
let tmp = [tmp0, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7, tmp8];
// Set 9 final results for all combinations of 3 rows starting at i and 3 rows starting at j
for (block_i, (r_row, tmp_row)) in r_row_block.chunks_exact_mut(n).zip(tmp.chunks_exact(BLOCK_HEIGHT)).enumerate() {
for (block_j, &tmp_res) in tmp_row.iter().enumerate() {
let res_i = i * BLOCK_HEIGHT + block_i;
let res_j = j * BLOCK_HEIGHT + block_j;
if res_i < n && res_j < n {
// Reduce one f32x8 to the final result for one pair of rows
r_row[res_j] = simd::horizontal_min(tmp_res);
}
}
}
}
};
r.par_chunks_mut(BLOCK_HEIGHT * n)
.zip(vd.par_chunks(BLOCK_HEIGHT * vecs_per_row))
.enumerate()
.for_each(step_row_block);
Benchmark
Let's run benchmarks with the same settings as before: n = 6000, single iteration, four threads bound to four cores.
C++ version available here.
| Implementation | Compiler | Time (s) | IPC |
|---|---|---|---|
C++ v4 | gcc 7.4.0-1ubuntu1 | 4.2 | 2.26 |
C++ v4 | clang 6.0.0-1ubuntu2 | 3.7 | 1.92 |
Rust v4 | rustc 1.38.0-nightly | 3.6 | 1.98 |
gcc
LOOP:
vmovaps ymm2,YMMWORD PTR [rdx]
vmovaps ymm14,YMMWORD PTR [rax]
lea rcx,[rdx+r8*1]
add rdx,0x20
vmovaps ymm1,YMMWORD PTR [rcx+r11*1]
vmovaps ymm0,YMMWORD PTR [rcx+rdi*1]
lea rcx,[rbx+rax*1]
add rax,0x20
vaddps ymm15,ymm2,ymm14
vmovaps ymm3,YMMWORD PTR [rcx+r15*1]
vmovaps ymm13,YMMWORD PTR [rcx+r14*1]
vminps ymm4,ymm4,ymm15
vaddps ymm15,ymm1,ymm14
vaddps ymm14,ymm0,ymm14
vminps ymm5,ymm5,ymm15
vmovaps YMMWORD PTR [rbp-0x170],ymm4
vminps ymm6,ymm6,ymm14
vaddps ymm14,ymm2,ymm3
vaddps ymm2,ymm2,ymm13
vmovaps YMMWORD PTR [rbp-0x150],ymm5
vminps ymm7,ymm7,ymm14
vaddps ymm14,ymm1,ymm3
vmovaps YMMWORD PTR [rbp-0x130],ymm6
vaddps ymm3,ymm0,ymm3
vaddps ymm1,ymm1,ymm13
vaddps ymm0,ymm0,ymm13
vminps ymm10,ymm10,ymm2
vminps ymm8,ymm8,ymm14
vmovaps YMMWORD PTR [rbp-0x110],ymm7
vminps ymm9,ymm9,ymm3
vminps ymm11,ymm11,ymm1
vminps ymm12,ymm12,ymm0
vmovaps YMMWORD PTR [rbp-0xb0],ymm10
vmovaps YMMWORD PTR [rbp-0xf0],ymm8
vmovaps YMMWORD PTR [rbp-0xd0],ymm9
vmovaps YMMWORD PTR [rbp-0x90],ymm11
vmovaps YMMWORD PTR [rbp-0x70],ymm12
cmp rax,rsi
jne LOOP
We see the expected output of 6 memory loads and 9+9 arithmetic instructions, but also quite a lot of register spilling in the middle and end of the loop.
It is unclear why the compiler decided to write intermediate results into memory already inside the loop, instead of keeping them in registers and doing the writing after the loop.
When compiling with gcc 9.1.0, these problems disappear.
clang
LOOP:
vmovaps ymm10,YMMWORD PTR [rdx+rbx*1]
vmovaps ymm11,YMMWORD PTR [rcx+rbx*1]
vmovaps ymm12,YMMWORD PTR [rax+rbx*1]
vmovaps ymm13,YMMWORD PTR [rbp+rbx*1+0x0]
vmovaps ymm14,YMMWORD PTR [rsi+rbx*1]
vmovaps ymm15,YMMWORD PTR [r8+rbx*1]
vaddps ymm0,ymm10,ymm13
vminps ymm9,ymm9,ymm0
vaddps ymm0,ymm11,ymm13
vminps ymm8,ymm8,ymm0
vaddps ymm0,ymm12,ymm13
vminps ymm7,ymm7,ymm0
vaddps ymm0,ymm10,ymm14
vminps ymm6,ymm6,ymm0
vaddps ymm0,ymm11,ymm14
vminps ymm5,ymm5,ymm0
vaddps ymm0,ymm12,ymm14
vminps ymm4,ymm4,ymm0
vaddps ymm0,ymm10,ymm15
vminps ymm3,ymm3,ymm0
vaddps ymm0,ymm11,ymm15
vminps ymm2,ymm2,ymm0
vaddps ymm0,ymm12,ymm15
vminps ymm1,ymm1,ymm0
add rdi,0x1
add rbx,0x20
cmp rdi,r10
jl LOOP
This is a fairly clean and straightforward loop with almost nothing extra.
We load 6 SIMD vectors to 256-bit registers ymm10-ymm15 and accumulate the results into 9 registers ymm1-ymm9, keeping ymm0 as a temporary variable.
Notice how rbx is incremented by 32 bytes at each iteration, which is the size of a 256-bit SIMD vector.
rustc
LOOP:
vmovaps ymm10,YMMWORD PTR [r9+rbx*1]
vmovaps ymm11,YMMWORD PTR [rax+rbx*1]
vmovaps ymm12,YMMWORD PTR [rcx+rbx*1]
vmovaps ymm13,YMMWORD PTR [r10+rbx*1]
vmovaps ymm14,YMMWORD PTR [r8+rbx*1]
vmovaps ymm15,YMMWORD PTR [rdx+rbx*1]
vaddps ymm0,ymm10,ymm13
vminps ymm9,ymm9,ymm0
vaddps ymm0,ymm10,ymm14
vminps ymm8,ymm8,ymm0
vaddps ymm0,ymm10,ymm15
vminps ymm7,ymm7,ymm0
vaddps ymm0,ymm11,ymm13
vminps ymm6,ymm6,ymm0
vaddps ymm0,ymm11,ymm14
vminps ymm5,ymm5,ymm0
vaddps ymm0,ymm11,ymm15
vminps ymm4,ymm4,ymm0
vaddps ymm0,ymm12,ymm13
vminps ymm3,ymm3,ymm0
vaddps ymm0,ymm12,ymm14
vminps ymm2,ymm2,ymm0
vaddps ymm0,ymm12,ymm15
vminps ymm1,ymm1,ymm0
add rbx,0x20
dec r13
jne LOOP
Same as clangs output, but instead of a loop counter that goes up, r13 is decremented on each iteration.