More register reuse
In this version, we will re-organize our SIMD-packed data in a way that allows us to do more arithmetic operations on the data after it has been loaded into the CPU registers.
Recall how in the previous implementation we performed 6 loads of f32x8 vectors and computed 9 f32x8 vectors worth of results in the performance critical loop.
Now, will perform 2 loads of f32x8 vectors and compute 8 f32x8 vectors worth of results.
This time, each f32x8 will contain 8 elements from 8 different rows instead of 8 elements from the same row.
As usual, the columns of vd are the rows of vt.
For each pair of f32x8 vectors from vd and vt, we will compute results for 8 different rows and 8 different columns, which means we can write 64 unique f32 results into r after each pass.
The approach is explained in detail with nice visualizations in the reference materials.
Implementation
We can keep most of the code from v4 as it is, but with some modifications.
First, we need to pack our SIMD vectors into a different order.
Fortunately, this is simply a matter of swapping some indexes.
Let's start by allocating some space for vd and vt.
Each row of f32x8s in vd corresponds to 8 rows of d, and each row of f32x8s in vt corresponds to 8 columns of d.
let vecs_per_col = (n + simd::f32x8_LENGTH - 1) / simd::f32x8_LENGTH;
// Like v4, but this time pack all elements of d into f32x8s vertically
let mut vd = std::vec![simd::f32x8_infty(); n * vecs_per_col];
let mut vt = std::vec![simd::f32x8_infty(); n * vecs_per_col];
The preprocessing will be very similar to v4, but this time we pack 8 rows and 8 columns of d into vd and vt, vertically as f32x8 vectors.
// Function: for row i of vd and row i of vt,
// copy 8 rows of d into vd and 8 columns of d into vt
let pack_simd_row_block = |(i, (vd_row, vt_row)): (usize, (&mut [f32x8], &mut [f32x8]))| {
for (jv, (vx, vy)) in vd_row.iter_mut().zip(vt_row.iter_mut()).enumerate() {
let mut vx_tmp = [std::f32::INFINITY; simd::f32x8_LENGTH];
let mut vy_tmp = [std::f32::INFINITY; simd::f32x8_LENGTH];
for (b, (x, y)) in vx_tmp.iter_mut().zip(vy_tmp.iter_mut()).enumerate() {
let j = i * simd::f32x8_LENGTH + b;
if i < n && j < n {
*x = d[n * j + jv];
*y = d[n * jv + j];
}
}
*vx = simd::from_slice(&vx_tmp);
*vy = simd::from_slice(&vy_tmp);
}
};
vd.par_chunks_mut(n)
.zip(vt.par_chunks_mut(n))
.enumerate()
.for_each(pack_simd_row_block);
Now all elements from d have been packed vertically into 8-row blocks.
Next, we will perform the step computations on all row blocks, such that the smallest unit of work for a thread is to compute 8 rows worth of results into r.
Before defining step_row_block, let's plan how we will divide the work into parallel threads.
Since one row of f32x8s in vd represents 8 rows of d, we will chunk r into blocks of 8 rows and chunk vd into single rows.
Then, we zip them up and apply step_row_block in parallel on all pairs:
// Function: for 8 rows in d, compute all results for 8 rows into r
let step_row_block = |(r_row_block, vd_row): (&mut [f32], &[f32x8])| {
// ...
};
// Chunk up r into row blocks containing 8 rows, each containing n f32s,
// and chunk up vd into rows, each containing n f32x8s
r.par_chunks_mut(simd::f32x8_LENGTH * n)
.zip(vd.par_chunks(n))
.for_each(step_row_block);
Now, for a 8-row block of d (vd_row), we need to compute 8n results into r by iterating over all 8-column blocks of d (row j of vt).
// Function: for 8 rows in d, compute all results for 8 rows into r
let step_row_block = |(r_row_block, vd_row): (&mut [f32], &[f32x8])| {
// Chunk up vt into rows, each containing n f32x8 vectors,
// exactly as vd_row
for (j, vt_row) in vt.chunks_exact(n).enumerate() {
// Intermediate results for 8 rows
let mut tmp = [simd::f32x8_infty(); simd::f32x8_LENGTH];
// ...
In the innermost loop, we loop over a pair of rows vd_row and vt_row.
For each pair of f32x8 vectors, we will compute 3 different permutations of the vector elements for vd_row and 1 permutation for vt_row.
Then, combining all permuted f32x8s, we accumulate 64 unique results for 8 rows and 8 columns of d.
We'll define a helper function simd::swap for inserting intrinsic functions that permute the elements of a f32x8.
// Iterate horizontally over both rows,
// permute elements of each `f32x8` to create 8 unique combinations,
// and compute 8 minimums from all combinations
for (&d0, &t0) in vd_row.iter().zip(vt_row) {
// Compute permutations of f32x8 elements
// 2 3 0 1 6 7 4 5
let d2 = simd::swap(d0, 2);
// 4 5 6 7 0 1 2 3
let d4 = simd::swap(d0, 4);
// 6 7 4 5 2 3 0 1
let d6 = simd::swap(d4, 2);
// 1 0 3 2 5 4 7 6
let t1 = simd::swap(t0, 1);
// Compute 8 independent, intermediate results for 8 rows
tmp[0] = simd::min(tmp[0], simd::add(d0, t0));
tmp[1] = simd::min(tmp[1], simd::add(d0, t1));
tmp[2] = simd::min(tmp[2], simd::add(d2, t0));
tmp[3] = simd::min(tmp[3], simd::add(d2, t1));
tmp[4] = simd::min(tmp[4], simd::add(d4, t0));
tmp[5] = simd::min(tmp[5], simd::add(d4, t1));
tmp[6] = simd::min(tmp[6], simd::add(d6, t0));
tmp[7] = simd::min(tmp[7], simd::add(d6, t1));
}
When we are done with the loop, we need to take care when extracting results from the 8 intermediate f32x8 results accumulated into tmp to make sure the indexes are mapped correctly back to r.
Since tmp contains 8 rows of f32x8 vectors, we need to extract 64 f32s into a 8-by-8 block in r.
The tricky part is that we have to somehow undo all the permutations.
Let's use a fixed, two-dimensional indexing pattern for writing f32s into a 8-by-8 block in r_row_block and figure out later how to read from the correct indexes in tmp.
We chunk r_row_block into 8 rows of length n and enumerate the rows by tmp_i.
Then we iterate over 8 elements starting at j * 8 of each row tmp_i in r_row_block and enumerate them by tmp_j, where j is the index of vt_row in vt.
Now we need to extract 64 f32 results from tmp and write them to row tmp_i and column tmp_j in the sub-block of 64 f32s in r_row_block, while taking into account that the elements in tmp are permuted.
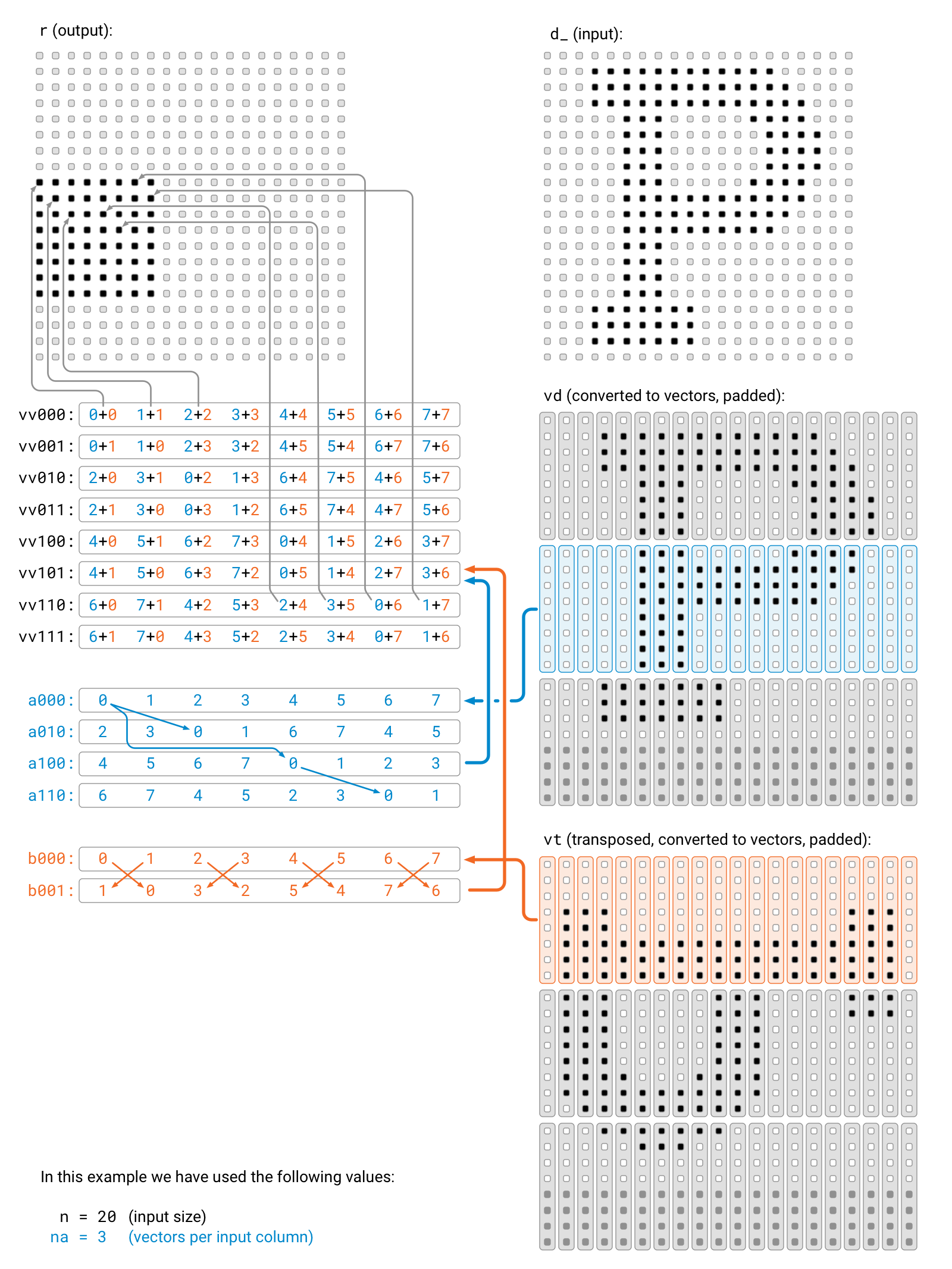
Consider this figure, and the 8-by-8 block on the left which shows the indexes of all elements in vv, i.e. our tmp.
Blue indexes on the left side of the plus sign equals tmp_i and orange indexes on the right side of the plus sign equals tmp_j.
If we permute the elements of rows with odd indexes by simd::swap(v, 1), you can see that the tmp_j indexes will follow 0..8 on every row.
More importantly, we can now retrieve the result for row tmp_i at column tmp_j from tmp at row tmp_i XOR tmp_j from element tmp_j.
{kind=link}
// Swap elements of f32x8s at odd indexes to enable a linear iteration
// pattern for index tmp_j when extracting elements
for i in (1..simd::f32x8_LENGTH).step_by(2) {
tmp[i] = simd::swap(tmp[i], 1);
}
// Set 8 final results (i.e. 64 f32 results in total)
for (tmp_i, r_row) in r_row_block.chunks_exact_mut(n).enumerate() {
for tmp_j in 0..simd::f32x8_LENGTH {
let res_j = j * simd::f32x8_LENGTH + tmp_j;
if res_j < n {
let v = tmp[tmp_i ^ tmp_j];
let vi = tmp_j as u8;
r_row[res_j] = simd::extract(v, vi);
}
}
}
Full step_row_block implementation
// Function: for 8 rows in d, compute all results for 8 rows into r
let step_row_block = |(r_row_block, vd_row): (&mut [f32], &[f32x8])| {
// Chunk up vt into rows, each containing n f32x8 vectors,
// exactly as vd_row
for (j, vt_row) in vt.chunks_exact(n).enumerate() {
// Intermediate results for 8 rows
let mut tmp = [simd::f32x8_infty(); simd::f32x8_LENGTH];
// Iterate horizontally over both rows,
// permute elements of each `f32x8` to create 8 unique combinations,
// and compute 8 minimums from all combinations
for (&d0, &t0) in vd_row.iter().zip(vt_row) {
// Compute permutations of f32x8 elements
// 2 3 0 1 6 7 4 5
let d2 = simd::swap(d0, 2);
// 4 5 6 7 0 1 2 3
let d4 = simd::swap(d0, 4);
// 6 7 4 5 2 3 0 1
let d6 = simd::swap(d4, 2);
// 1 0 3 2 5 4 7 6
let t1 = simd::swap(t0, 1);
// Compute 8 independent, intermediate results for 8 rows
tmp[0] = simd::min(tmp[0], simd::add(d0, t0));
tmp[1] = simd::min(tmp[1], simd::add(d0, t1));
tmp[2] = simd::min(tmp[2], simd::add(d2, t0));
tmp[3] = simd::min(tmp[3], simd::add(d2, t1));
tmp[4] = simd::min(tmp[4], simd::add(d4, t0));
tmp[5] = simd::min(tmp[5], simd::add(d4, t1));
tmp[6] = simd::min(tmp[6], simd::add(d6, t0));
tmp[7] = simd::min(tmp[7], simd::add(d6, t1));
}
// Swap elements of f32x8s at odd indexes to enable a linear iteration
// pattern for index tmp_j when extracting elements
for i in (1..simd::f32x8_LENGTH).step_by(2) {
tmp[i] = simd::swap(tmp[i], 1);
}
// Set 8 final results (i.e. 64 f32 results in total)
for (tmp_i, r_row) in r_row_block.chunks_exact_mut(n).enumerate() {
for tmp_j in 0..simd::f32x8_LENGTH {
let res_j = j * simd::f32x8_LENGTH + tmp_j;
if res_j < n {
let v = tmp[tmp_i ^ tmp_j];
let vi = tmp_j as u8;
r_row[res_j] = simd::extract(v, vi);
}
}
}
}
};
// Chunk up r into row blocks containing 8 rows, each containing n f32s,
// and chunk up vd into rows, each containing n f32x8s
r.par_chunks_mut(simd::f32x8_LENGTH * n)
.zip(vd.par_chunks(n))
.for_each(step_row_block);
Benchmark
Let's run benchmarks with the same settings as before: n = 6000, single iteration, four threads bound to four cores.
C++ version available here.
| Implementation | Compiler | Time (s) | IPC |
|---|---|---|---|
C++ v5 | gcc 7.4.0-1ubuntu1 | 2.4 | 2.46 |
C++ v5 | clang 6.0.0-1ubuntu2 | 2.6 | 2.06 |
Rust v5 | rustc 1.38.0-nightly | 2.5 | 2.54 |
The lower IPC for clang might be due to lower usage of CPUs (2.5 CPUs) than in other versions (3.5 CPUs).
The reason for this is still unclear.
Assembly
All 3 compilers produced similar loops, which all load two f32x8s, perform 4 permutations, and compute 8 additions and 8 minimums.
One notable difference is that gcc performs all permutations using 32-bit and 128-bit lanes, while both clang and rustc load one register as double-precision floats and do permutations using 32-bit and 64-bit lanes.
gcc
LOOP:
vmovaps ymm2,YMMWORD PTR [rdx+rax*1]
vmovaps ymm3,YMMWORD PTR [rcx+rax*1]
add rax,0x20
vpermilps ymm0,ymm2,0xb1
vperm2f128 ymm13,ymm3,ymm3,0x1
vpermilps ymm14,ymm3,0x4e
vaddps ymm15,ymm3,ymm2
vaddps ymm3,ymm3,ymm0
vpermilps ymm1,ymm13,0x4e
vminps ymm7,ymm7,ymm3
vaddps ymm3,ymm2,ymm14
vaddps ymm14,ymm0,ymm14
vminps ymm9,ymm9,ymm15
vminps ymm10,ymm10,ymm3
vaddps ymm3,ymm2,ymm13
vaddps ymm13,ymm0,ymm13
vaddps ymm2,ymm2,ymm1
vaddps ymm0,ymm0,ymm1
vminps ymm6,ymm6,ymm14
vminps ymm11,ymm11,ymm3
vminps ymm5,ymm5,ymm13
vminps ymm8,ymm8,ymm2
vminps ymm4,ymm4,ymm0
cmp rax,r12
jne LOOP
clang
LOOP:
vmovapd ymm9,YMMWORD PTR [rax+rsi*1]
vmovaps ymm10,YMMWORD PTR [rcx+rsi*1]
vpermpd ymm11,ymm9,0x4e
vpermilpd ymm12,ymm9,0x5
vpermilpd ymm13,ymm11,0x5
vpermilps ymm14,ymm10,0xb1
vaddps ymm15,ymm9,ymm10
vminps ymm5,ymm5,ymm15
vaddps ymm9,ymm9,ymm14
vminps ymm4,ymm4,ymm9
vaddps ymm9,ymm12,ymm10
vminps ymm6,ymm6,ymm9
vaddps ymm9,ymm12,ymm14
vminps ymm3,ymm3,ymm9
vaddps ymm9,ymm11,ymm10
vminps ymm7,ymm7,ymm9
vaddps ymm9,ymm11,ymm14
vminps ymm2,ymm2,ymm9
vaddps ymm9,ymm10,ymm13
vminps ymm8,ymm8,ymm9
vaddps ymm9,ymm13,ymm14
vminps ymm1,ymm1,ymm9
add rdi,0x1
add rsi,0x20
cmp rdi,r15
jl LOOP
rustc
LOOP:
inc rdx
vmovapd ymm9,YMMWORD PTR [rcx+rax*1]
vmovaps ymm10,YMMWORD PTR [r9+rax*1]
vpermilpd ymm11,ymm9,0x5
vpermpd ymm12,ymm9,0x4e
vpermpd ymm13,ymm9,0x1b
vpermilps ymm14,ymm10,0xb1
vaddps ymm15,ymm9,ymm10
vminps ymm8,ymm8,ymm15
vaddps ymm9,ymm9,ymm14
vminps ymm7,ymm7,ymm9
vaddps ymm9,ymm11,ymm10
vminps ymm6,ymm6,ymm9
vaddps ymm9,ymm11,ymm14
vminps ymm5,ymm5,ymm9
vaddps ymm9,ymm12,ymm10
vminps ymm4,ymm4,ymm9
vaddps ymm9,ymm12,ymm14
vminps ymm3,ymm3,ymm9
vaddps ymm9,ymm10,ymm13
vminps ymm2,ymm2,ymm9
vaddps ymm9,ymm13,ymm14
vminps ymm1,ymm1,ymm9
add rax,0x20
cmp rdx,rsi
jb LOOP